Arize Phoenix: up and running
Table of Contents
Arize Phoenix is an open-source Python library built by Arize AI. It’s designed to help AI engineers to trace, evaluate, experiment, and optimize AI applications in development.
This article covers everything you need to get Arize Phoenix operational - from initial setup to running your first evaluation on macOS.
Why Arize Phoenix? #
While evaluating observability and monitoring tools for AI applications, we explored multiple options to enhance our workflow. Our key requirements included open-source software, self-hosted infrastructure, and compatibility with diverse AI models. Arize Phoenix meets all these criteria.
As someone new to Python, I particularly appreciated its intuitive interface and user-friendly approach, which made implementation and adoption remarkably straightforward. Additionally, I got a lot of help from its Slack community.
Requirements #
Python package manager #
uv1 is the only tool you’ll install.
- Homebrew
brew install uv
- PyPI
pipx install uv
See the official guide for other choices.
LLM API key #
Arize Phoenix supports various LLM providers for evaluations. This article uses LiteLLMModel with OpenRouter2. Grab the API key here: https://openrouter.ai/settings/keys.
Installation #
Create a project #
$ uv init my-project
Initialized project `my-project` at `/Users/james/tmp/my-project`
$ tree my-project/
my-project/
├── README.md
├── hello.py
└── pyproject.toml
1 directory, 3 files
Install Arize Phoenix #
$ cd my-project
$ uv add arize-phoenix litellm arize-phoenix-otel openinference-instrumentation-litellm
uv will install the arize-phoenix package and its dependencies in a virtual environment at my-project/.venv/ directory.
Evaluation #
Start the Python REPL #
$ uv run python
Set API key #
import os
from getpass import getpass
os.environ["OPENROUTER_API_KEY"] = getpass("🔑 Enter your OpenRouter API key: ")
Run evaluation #
import pandas as pd
from phoenix.evals import LiteLLMModel, QAEvaluator, run_evals
df = pd.DataFrame(
[
{
"input": "Where is Oriental Pearl Tower located?",
"reference": "The Oriental Pearl Tower[a] is a futurist TV tower in Lujiazui, Shanghai.",
"output": "It's located in Lujiazui, Shanghai.",
},
{
"input": "Is Oriental Pearl Tower the tallest in China?",
"reference": "Built from 1991 to 1994, the tower was the tallest structure in China until the completion of nearby World Financial Center in 2007.",
"output": "It's the tallest in China.",
}
]
)
eval_model = LiteLLMModel(model="openrouter/openai/gpt-4o-mini")
qa_evaluator = QAEvaluator(eval_model)
qa_eval_df = run_evals(
dataframe=df,
evaluators=[qa_evaluator],
provide_explanation=True,
)
run_evals returns a list of DataFrames. Let’s see the evaluation result:
>>> print(qa_eval_df)
[ label score explanation
0 correct 1 To determine if the answer is correct, we firs...
1 incorrect 0 To determine whether the answer correctly addr...]
>>> qa_eval_df[0].loc[0, 'explanation']
'To determine if the answer is correct, we first need to analyze the question, the reference text, and the answer provided.\n\n1. **Identify the Question**: The question asks, "Where is Oriental Pearl Tower located?" This is a straightforward inquiry about the geographical location of the Oriental Pearl Tower.\n\n2. **Examine the Reference Text**: The reference text states, "The Oriental Pearl Tower is a futurist TV tower in Lujiazui, Shanghai." This sentence provides a clear location for the Oriental Pearl Tower, specifying that it is in Lujiazui, which is a district in Shanghai.\n\n3. **Analyze the Answer**: The answer given is, "It\'s located in Lujiazui, Shanghai." This response directly addresses the question by repeating the location mentioned in the reference text.\n\n4. **Compare the Answer to the Reference**: The answer matches the information provided in the reference text. It specifies both the district (Lujiazui) and the city (Shanghai), which fully answers the question about the location of the Oriental Pearl Tower.\n\n5. **Conclusion**: Since the answer accurately reflects the information found in the reference text and fully answers the question, we can conclude that the answer is correct.\n\nLABEL: correct'
>>> qa_eval_df[0].loc[1, 'explanation']
'To determine whether the answer correctly addresses the question, we need to analyze both the question and the reference text.\n\n1. **Understanding the Question**: The question asks if the Oriental Pearl Tower is the tallest structure in China. This requires a definitive answer regarding its height in comparison to other structures in China.\n\n2. **Analyzing the Reference Text**: The reference states that the Oriental Pearl Tower was the tallest structure in China until the completion of the World Financial Center in 2007. This indicates that the Oriental Pearl Tower is no longer the tallest structure in China, as it was surpassed by another building.\n\n3. **Evaluating the Answer**: The answer provided is "It\'s the tallest in China." This statement directly contradicts the information in the reference text, which clearly states that the Oriental Pearl Tower was the tallest until 2007, implying that it is not currently the tallest.\n\n4. **Conclusion**: Since the answer claims that the Oriental Pearl Tower is still the tallest in China, but the reference text indicates that it is not, the answer does not correctly answer the question.\n\nLABEL: incorrect'
Great! You’ve just completed your first evaluation.
Visualization #
Phoenix includes a web interface to visualize evaluation results. Let’s adjust our first evaluation to make these results visible in the UI.
Start Phoenix server #
$ uv run phoenix serve
...omitted...
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:6006 (Press CTRL+C to quit)
Phoenix is running. Open your web browser and navigate to http://127.0.0.1:6006 to access the web UI.
Enable traces #
from phoenix.otel import register
from openinference.instrumentation.litellm import LiteLLMInstrumentor
tracer_provider = register(
project_name="my-project",
endpoint="http://localhost:6006/v1/traces",
)
LiteLLMInstrumentor().instrument(tracer_provider=tracer_provider)
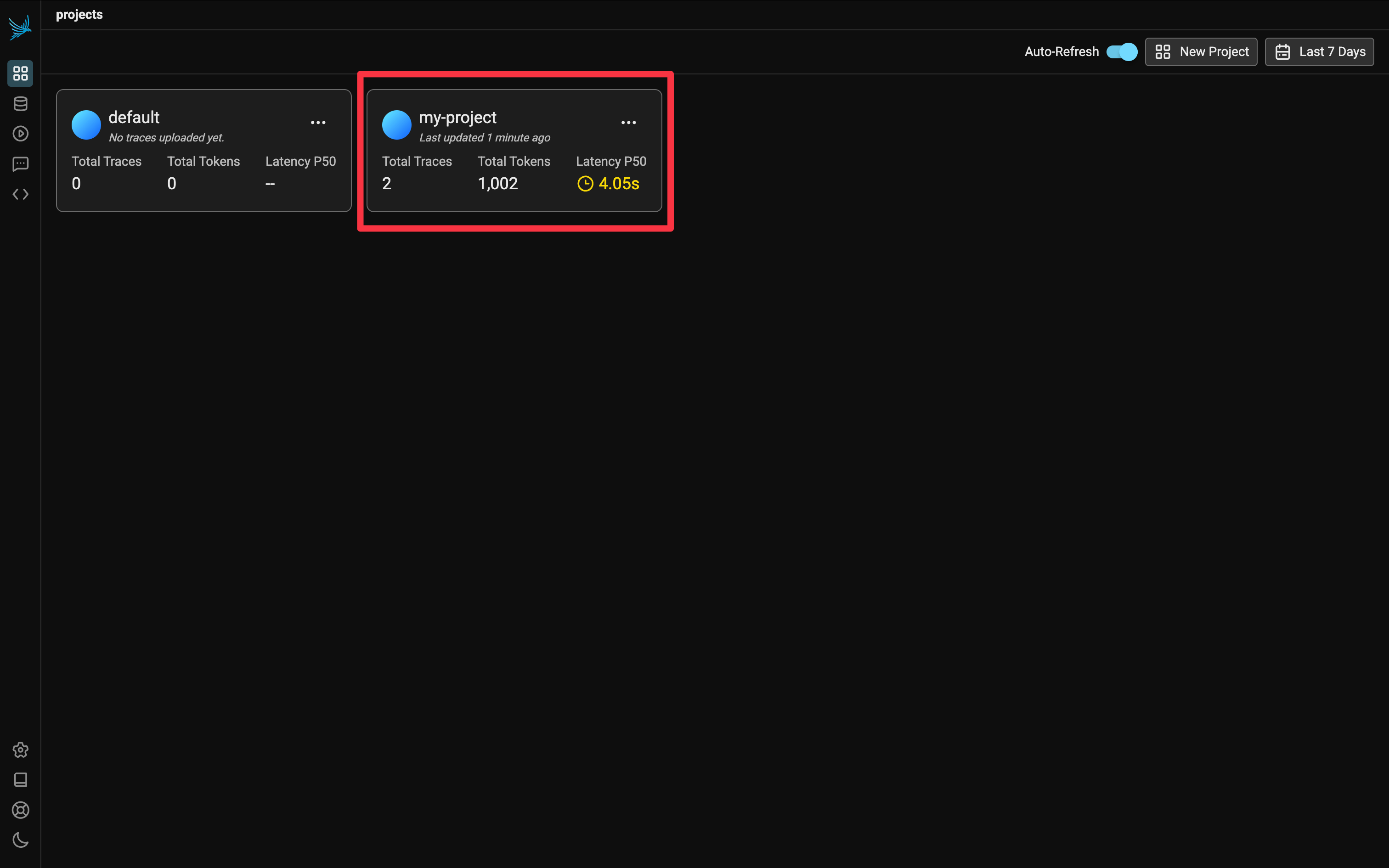
Repeat the Evaluation, and open http://127.0.0.1:6006 again, you’ll see a new project called my-project:
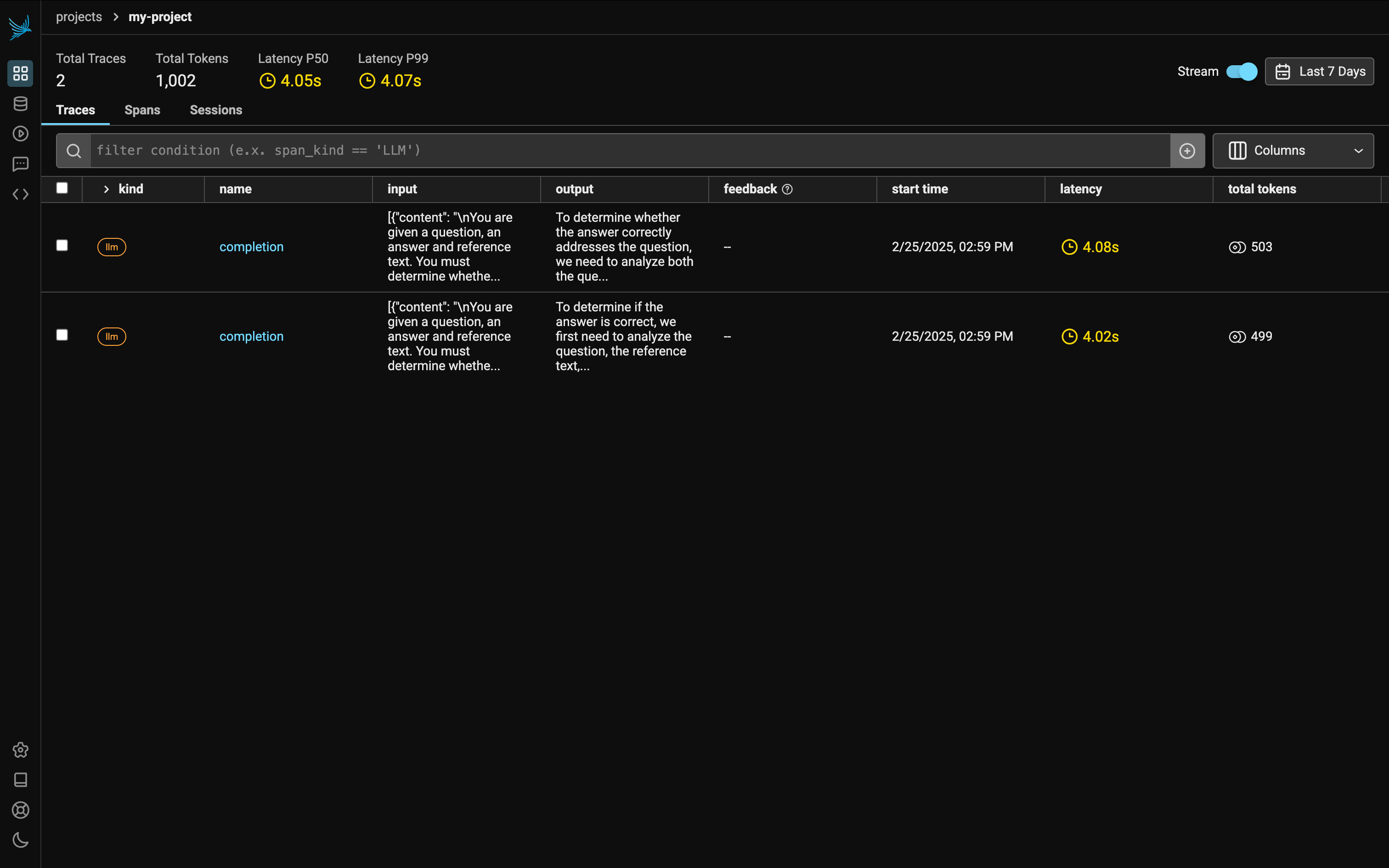
Click my-project and there are two llm traces:
Conclusion #
In this article, you learned how to evaluate LLM and view traces in Phoenix. Stay tuned for our next article, which will cover how to provide feedback on evaluations.
uv is an extremely fast Python package and project manager. ↩︎
OpenRouter provides access to AI models from multiple providers and platforms. ↩︎